1. 功能结构图
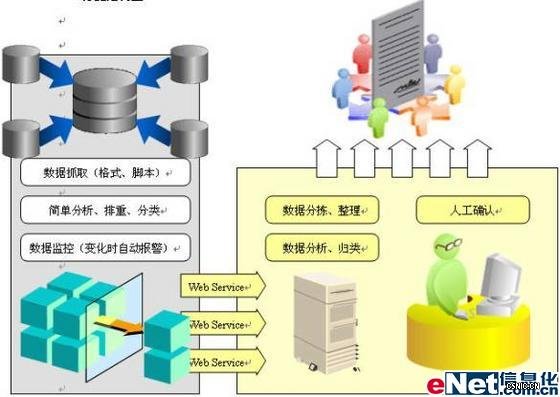
图4-1 系统功能结构图
2. 定义格式,编制脚本
首先,我们需要根据需要抓取的目标网站的特点,编制抓取的脚本(格式)。包括:
● 目标网站的URL路径;
● 用什么样的方法获取数据?可以用模拟查询功能的方法(手工检测查询页面提交的参数,并模拟提交);也可以通过序列号从头到尾进行遍历(需要找出当前最大的序列号值);
● 针对每个网站的特点进行编制(标准、脚本);
3. 抓取数据
系统所提供的耙子程序会根据预先定义好的XML格式执行数据抓取任务,为防止目标网站的侦测程序发现,我们建议将抓取到的页面直接保存,然后再作处理。而不是在获得信息后立即加以处理,这对于提高抓取的效率和保留第一手的资料都是非常有价值的。
● 通过定义好的脚本模拟登录;
● 对下拉列表中的查询项,用循环遍历列表中的每一个值。并对查询出结果的页面进行模拟翻页操作,获得其所有的查询结果;
● 如果职位库或企业名录库是使用自增性的整数作为其唯一标示的ID,那么我们可以想办法获得其最大值,然后通过遍历的方法将其全部抓取下来;
● 定期执行抓取操作,并对抓取到的数据进行增量保存;
4. 简单分析
在外网的服务器上对采集到的数据进行简单的分析、处理,其内容主要包括:
● 结构化数据:将获取到的数据结构化,可以便于未来的数据传递,也便于下一步的排重、排错检查任务。
● 排除重复;在用模拟查询的方法进行遍历的时候,系统所抓取到的数据一定会出现重复。由于重复数据会造成重复的分析处理过程,不但占用了系统的资源,使得系统的处理效率变低,也给系统带来大量的垃圾数据。为了避免大量重复、冗余的数据出现,我们首先要作的处理工作就是排重。
● 排除错误;由于目标站点的内容、结构、格式的调整,会造成系统抓取失败,或抓取到大量的错误信息,在排除这些误抓的信息的同时,我们通过对数据错误率的判断,可以获得目标站点是否已经变更的信息,及时向系统发出预警通知。
